
Enabling Modular Torch Models in DeepChem
Background:
Transfer learning is a technique in machine learning where a model trained on one task is used as the starting point for a model on a second, related task. This is commonly known as pretraining and fine-tuning, respectively. This can be useful because it allows the model to start with knowledge already learned from the first task, rather than starting from scratch, which can save time and resources. It is particularly useful when there is a shortage of labeled data for the second task.
Abstract:
This proposal outlines the addition of a ModularTorchModel class to DeepChem. The ModularTorchModel class allows users to modify the structural components of a model and specify a loss function which accesses those components. This may be useful in loading only specific components of a pretrained model, enabling pretrained components from different models to be combined into a single model. This may also be helpful for pretraining tasks in which an intermediate output from a model is required to calculate the loss, as opposed to a typical loss which uses only the output of a full forward pass.
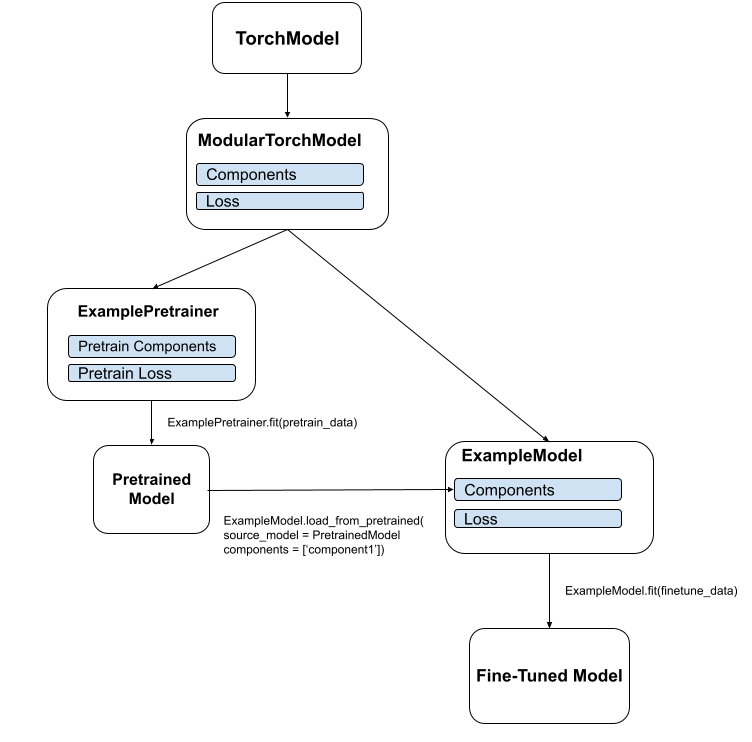
Motivation:
In many applications, we may want to fine-tune a pre-trained model to a new task while reusing the majority of the model’s knowledge and architecture. Pretrained models act as a foundation for new development into more specific tasks. Finetuning can save time and computational resources compared to training a new model from scratch each time, and enables transfer learning between datasets. By removing friction in generating and loading new pretrained model components, users can focus more effort on innovative research code and less effort on engineering pretraining pipelines.
Outline:
-
Implement the ModularTorchModel abstract class as a subclass of TorchModel. This class implements 5 modified or new methods and 1 private attribute.
- build_components(): This generates a dictionary of the names of the components and their associated layers.
- build_model(): Using the components dictionary, creates the full model to be used for inference.
- loss_func(): This is a loss function which is specific to that particular model. This is responsible for generating the loss given the model’s components.
- load_from_pretrained(): Similar to the TorchModel load from pretrained, except that it adds an argument ‘components’ which allows the user to specify which components to load.
- fit_generator(): Similar to the TorchModel fit_generator, except that it is compatible with the custom loss_func().
- ‘components’ attribute: a private attribute of the components dictionary.
-
Test that ModularTorchModel functions similarly to TorchModel, with the addition of testing loading specific components.
- Overfit test
- Fit restore test
- Load from pretrained with specific components
- Freeze embedding and finetune test
No breaking changes will be made.
Abstract class:
class ModularTorchModel(TorchModel):
def __init__(self, model:nn.Module, components:dict, **kwargs):
self.model = model
self.components = components
super().__init__(self.model, self.loss_func, **kwargs)
def build_model(self):
return NotImplementedError("Subclass must define the components")
def build_components(self):
return NotImplementedError("Subclass must define the components")
def loss_func(self):
return NotImplementedError("Subclass must define the loss function")
def load_from_pretrained(self, source_model: ModularTorchModel = None, checkpoint: Optional[str] = None, model_dir: str = None, components: list = None):
# generate the source state dict
if source_model is not None:
source_state_dict = source_model.model.state_dict()
elif checkpoint is not None:
source_state_dict = torch.load(checkpoint)['model_state_dict']
elif model_dir is not None:
checkpoints = sorted(self.get_checkpoints(model_dir))
source_state_dict = torch.load(checkpoints[0])['model_state_dict']
else:
raise ValueError("Must provide a source model, checkpoint, or model_dir")
if components is not None: # load the specified components
if source_model is not None:
assignment_map = {k: v for k, v in source_model.components.items() if k in components}
self.components.update(assignment_map)
self.model = self.build_model()
else:
raise ValueError("If loading from checkpoint, you cannot pass a list of components to load")
else: # or all components with matching names and shapes
model_dict = self.model.state_dict()
assignment_map = {k: v for k, v in source_state_dict.items() if k in model_dict and v.shape == model_dict[k].shape}
model_dict.update(assignment_map)
self.model.load_state_dict(model_dict)
def fit_generator(self, generator) #abbreviated, lines modified from TorchModel are commented out
...
# outputs = self.model(inputs)
# if isinstance(outputs, torch.Tensor):
# outputs = [outputs]
# if self._loss_outputs is not None:
# outputs = [outputs[i] for i in self._loss_outputs]
# batch_loss = loss(outputs, labels, weights)
batch_loss = self.loss_func(inputs, labels, weights)
Usage:
example_model = ExampleTorchModel(n_feat, d_hidden, n_layers, ft_tasks)
example_pretrainer = ExamplePretrainer(example_model, pt_tasks)
example_pretrainer.fit(dataset_pt, nb_epoch=1000)
example_model.load_from_pretrained(source_model = example_pretrainer, components=['encoder'])
example_model.fit(dataset_ft, nb_epoch=1000)
More realistic example:
GAN_model = GAN(generator, discriminator)
pretrained_discriminator = classifier(input_dim, output_dim)
pretrained_discriminator.restore('checkpoint.ckpt')
GAN_model.load_from_pretrained(source_model = pretrained_discriminator, components=['discriminator'])
GAN_model.fit(dataset_ft, nb_epoch=1000)