
I recently read the paper Deep Learning Model for Finding New Superconductors. As a brief high level summary, this work designs a deep learning architecture for superconducting materials design and trains it from a historical database of known superconductors. They then test this model (trained on historical data) on a variety of recently discovered superconducting materials to see whether their model could have aided in materials discovery.
There are a lot of interesting tidbits in this paper. The authors note that in a recent screen for superconducting materials, only 3% of materials screened were superconducting. These numbers should sound familiar to anyone who’s worked with pharmaceutical screening data where “hit” rates of a few percent are standard. The authors note that at present screening depends on experimental intuition and is mostly trial and error. One of the broad dreams of scientific deep learning is to take human gut feeling analyses like these and turn them into reproducible processes. The design of a room temperature superconductor is one of science’s grand challenges, so it would be amazing to see deep learning play a role in solving this open problem. Let’s dive into some of the technical details in this paper.
The authors start by noting that in many ways the machine learning challenge faced in superconductor design is much harder than that faced in classical machine learning. We have no training data yet that gives us a clue what a higher temperature superconductor might look like. The paper suggests that this is a type of “zero shot learning” problem. This is an interesting bit of phrasing since zero-shot learning is more often used in tasks like translating a new language with no existing training data. I’d argue that the challenge here is more one of suitable generalizability rather than zero shot learning, although I’m perhaps just picking at semantic quibbles. The paper notes that although classical physical theories like BCS theory provide some guidance, known higher temperature superconductors such as cuprates have complex strong electron correlations that foil classical computational techniques.
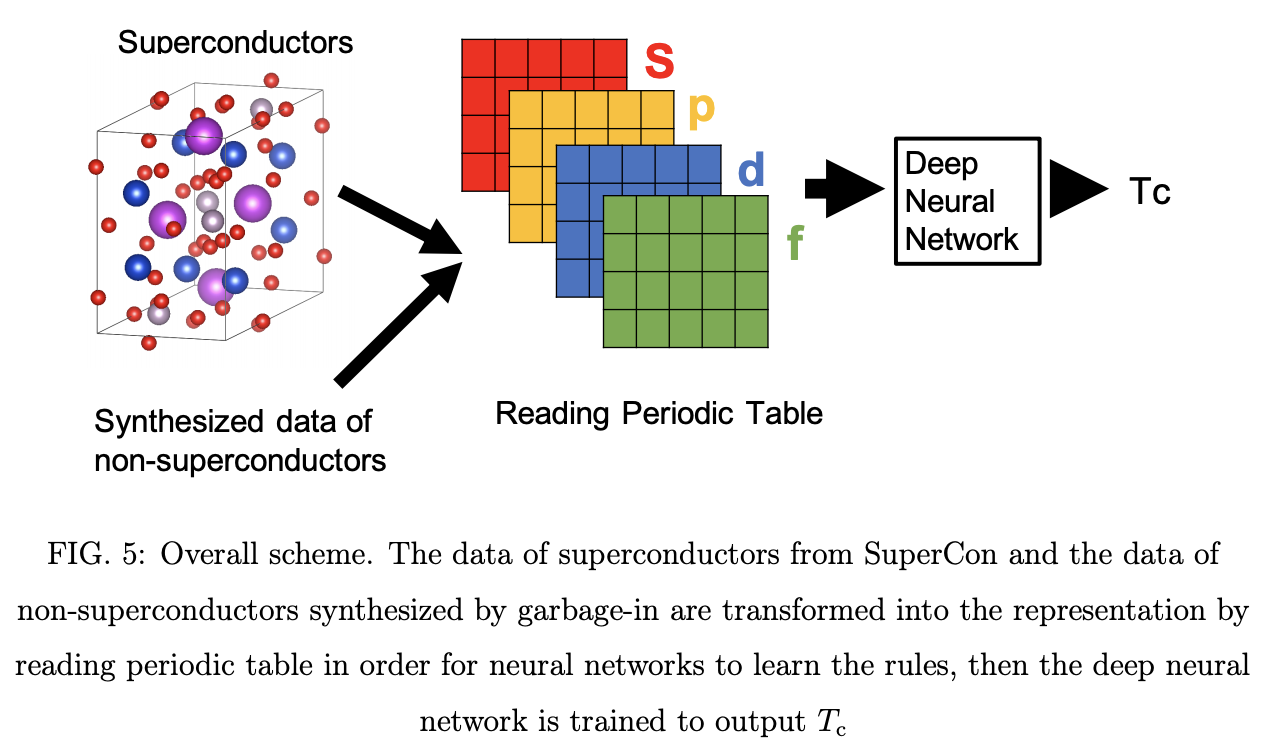
One of the most interesting ideas from this paper is their framework for featurizing a superconducting material, the periodic table featurization scheme. The authors didn’t have access to a spatial representation of the superconductors in question, so they simply encoded them as entries in the periodic table! How does this work? It might be easiest to look at the picture below. The basic idea is that the authors take the periodic table as a subset of a 2 dimensional rectangle. They then encode the fraction of the compound that belongs to each element. I found it useful to think of this as a type of two-dimensional one-hot encoding. They then do one additional split into s/p/d/f orbitals to represent the orbital characteristics of the valence electrons. This split allows the networks to learn to compute on the valence orbital blocks.

It’s worth noting that “imagification” is now a common technique in scientific deep learning. This has been used before for molecules, genetic sequences, microscopy and probably a number of other applications as well. The basic motivation is simple. By encoding a scientific structure as a simple 2D image, scientists can repurpose the extraordinary amount of research that’s gone into computer vision. I’d argue this technique isn’t just a “hack”. The periodic table for example was designed to structurally encode useful properties in a way that the human visual system could process. Given the relationships between convolutional neural networks and the human visual cortex, it’s not too far a stretch to claim that the visual encodings succeed in capturing some fraction of the human scientist’s encoding.
The network is trained on inorganic super conductor data from the SuperCon database of known superconductors. For machine learning folks, here’s a nice processed version of SuperCon that was used in another paper, but which doesn’t contain time-split information (which we will see was used extensively in this paper). The preliminary model they trained achieves .92 test R^2 accuracy. Here’s a scatter plot of predictions made versus actual superconducting temperature.
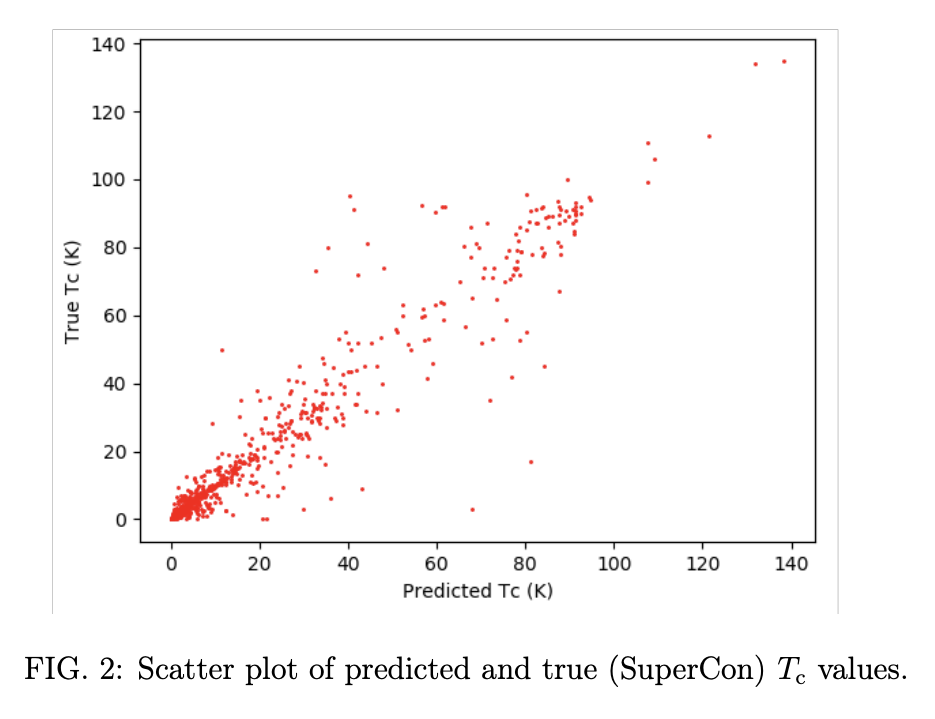
Models were trained with Adam for 6,000 epochs with batch size 32 and learning rate 2 \times 10^{-6}. Models were 64 convolutional layers deep. Training took about 50 hours on their setup.
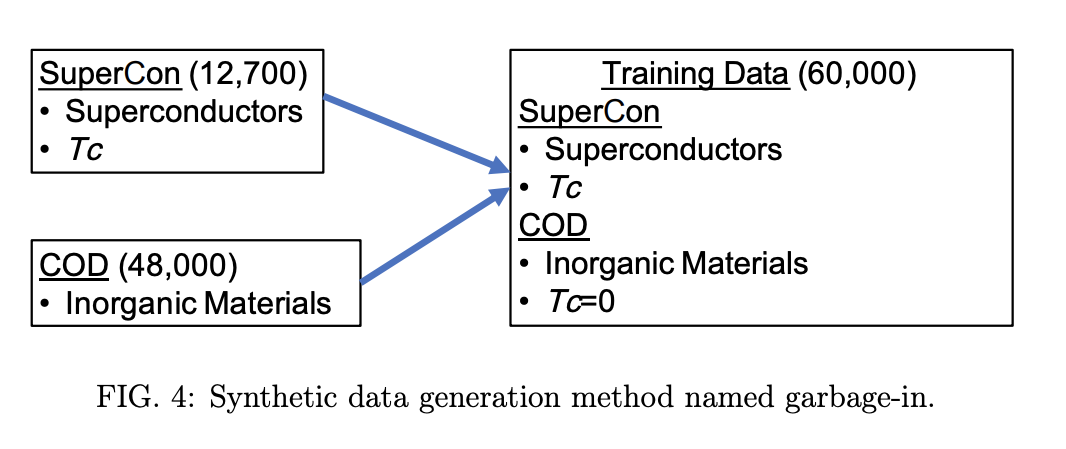
The paper applied this model to make predictions on the crystallography open database (COD). The authors found that their trained models predicted that 17,000 compounds from COD were predicted to have T_c (superconducting temperatures) over 10K, which is physically unrealistic. The paper reasons that this is likely due to the fact that the SuperCon dataset has very few non-superconductors (only 60), so the model has a bias from its training data.
To solve this issue, the authors come up with a clever data augmentation strategy, which they aptly title “garbage in”. They took all compounds from COD which were not in SuperCon and reasoned that these compounds were unlikely to be superconducters, and so added them as training samples with T_c = 0. This figure below summarizes the data sourcing strategy:
Here’s the joint training scheme rendered with this data augmentation strategy
To test this joint model, the authors source another dataset of materials discovered since 2010 (reference). This dataset contains 400 compounds with 330 non-superconductors. To remove potential information leakage, the authors time-split SuperCon and COD and use only compounds added before 2010 as training data. Here are some results from their models on this dataset
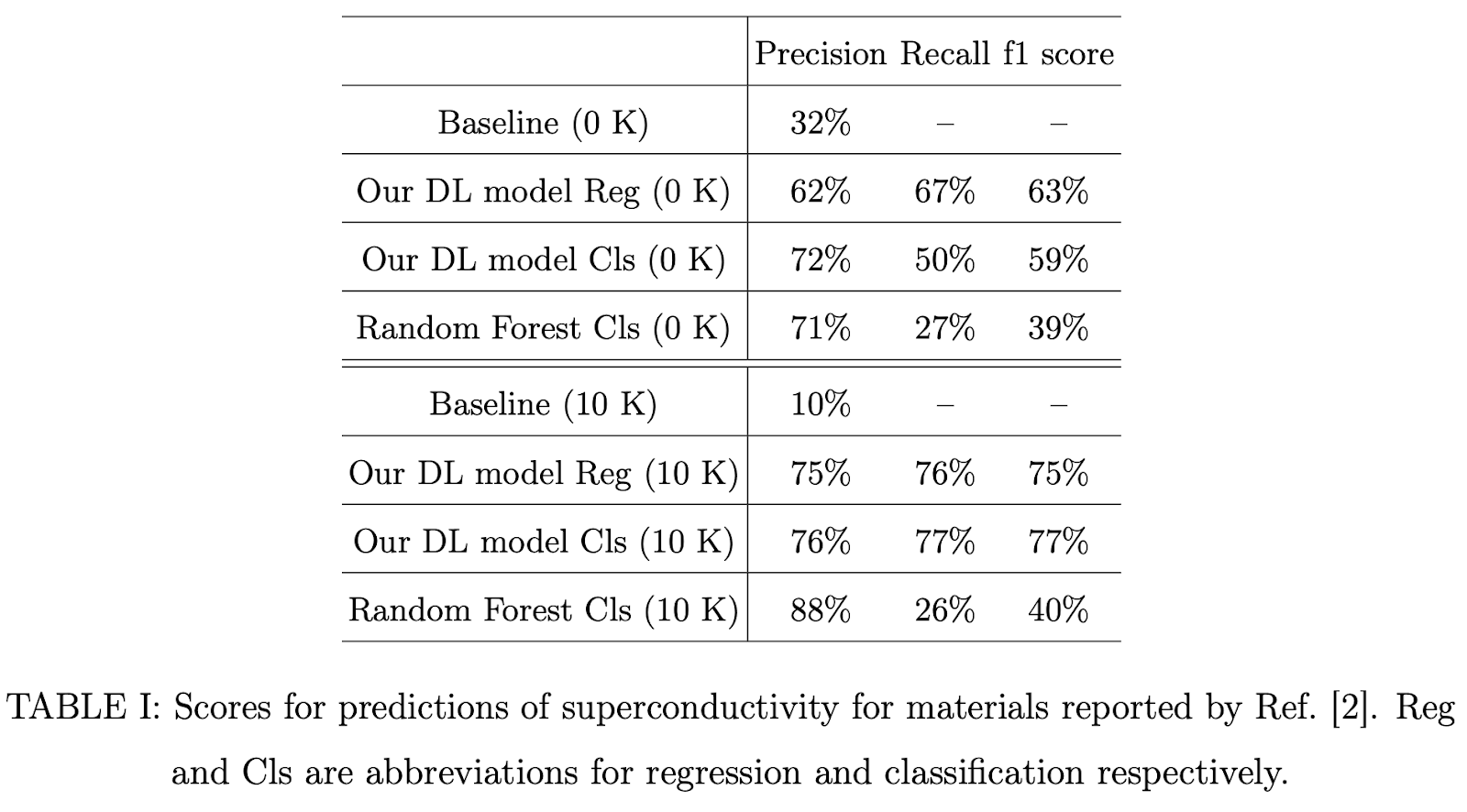
The baseline here was randomly selecting any compound from this dataset and predicting it to have T_c > 0. The authors also compare against a Random Forest baseline which uses manually designed features such as atomic mass, band gap, atomic configuration and melting temperature. The table above also has a second comparison for T_c > 10 predictions (since only a few superconductors have this higher superconducting temperature). The baseline does much worse in this case. The authors note that precision and recall is much higher for the deep learned model over the baseline in both cases. Comparison against the random forest is a little more muddled, but it’s not unreasonable to say the deep learning model has stronger performance (although I’d have liked to see error bars here).
The authors also re-test the trained model against the COD database. I was a little confused by this comparison since COD was made part of the training data! I think the authors were looking to see what the trained model predicted on its own training data to see where the model predicted something that didn’t match the synthetic label of T_c = 0. The authors note that they identified \textrm{CaBi}_2 with this technique, a recently discovered superconductor not in SuperCon.
As a third test, the authors use training data sourced from before 2008 to see if they can find high-T_c \textrm{Fe} based superconductors (FeSCs), which were first discovered in 2008. Two precursor materials, LaFePO and LaFePFO were also removed from the training data since their discovery in 2006 spurred the development of FeSCs. 1,399 FeSCs known as of 2018 were used as the test set. 130 different training runs were used, which lead to stochastic variation in the predictions. The histogram below plots the number of predicted FeSCs on the test set from these various trained models. The authors note that when they used a shallower 10 layer network (which had similar precision and R^2 as their models), they failed to identify FeSCs, and mused that the depth of their networks may lead to greater generalizability.
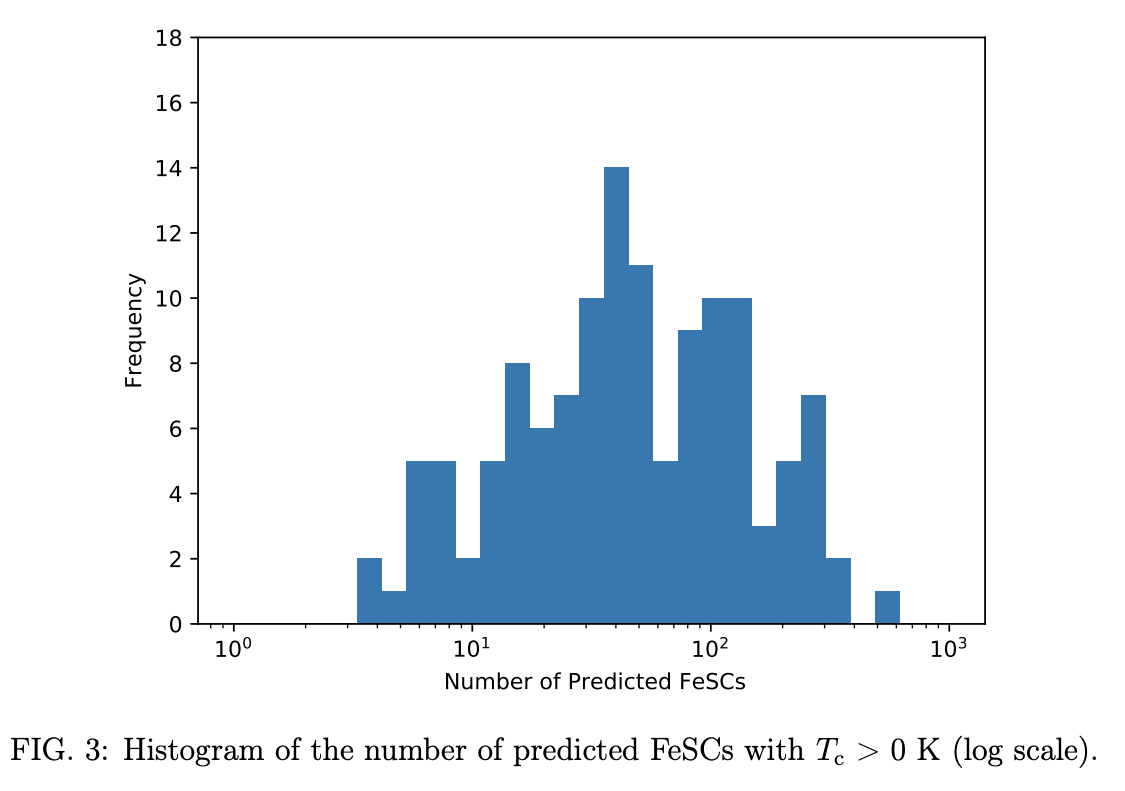
The authors suggest that had their models been used earlier, they could have aided in the discovery of FeSCs, but acknowledge that the model spread noted in the figure above could have meant FeSCs were a lower priority target. The authors mention that they’re planning to attempt to use crystal structure data in future work to see if they can achieve higher predictive performance.
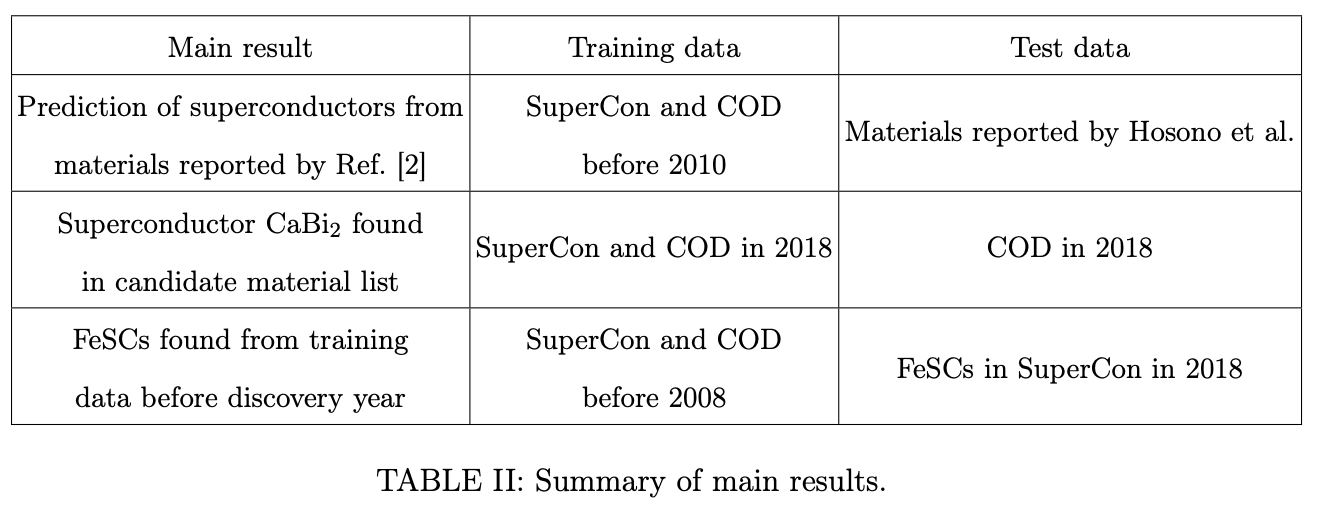
One thing I really liked about this paper was the emphasis on using time splits to validate the generalizability of the model. The variety of different test sets makes a stronger case that deep learning can serve as a useful tool in superconductor discovery. Here’s a table that summarizes the various train/test splits that the authors used to validate their models
The authors note that they plan to open source their code, but are waiting until they can run a few experiments with novel compounds that they’ve predicted. I hope that they also open source a clean form of their datasets. The raw SuperCon database doesn’t have a clean download option, and it might be a little tricky to reproduce their training/test splits without this additional information. It would also be very convenient to have nice versions of their FeSCs and other test datasets.